
Je suis Enguerrand Doucet, Data Architect chez Winston Advisory. Dans cette série consacrée à la construction d’une plateforme dédié à l’Analytics, je vous guide à travers les principales étapes pour monter votre paysage décisionnel.
Cet article ne s’adresse pas uniquement aux professionnels de la data : il vise un public plus large, notamment les DSI, chefs de projet ou décideurs souhaitant comprendre la logique globale d’un projet de plateforme data & analytics, de la conception jusqu’à la mise en service.
Je propose donc pour toute personne souhaitant s’engager dans un projet de transformation data de partager quelques clés pour réussir.
Nous allons aborder en première partie la façon de déterminer l’enveloppe globale de votre projet. Pour ce faire nous allons passer en revue détaillée les types de coûts : investissement, fonctionnement, tarification, coûts indirects.
Dans un second temps, pour vous aider à monter l’argumentaire de votre projet, nous allons également aborder les bénéfices attendus d’un projet Data : transformation des processus par l’automatisation des traitements de données, amélioration du pilotage de la performance, meilleure gouvernance de la donnée.
J’ai cherché à rendre le propos accessible tout en étant précis et en partageant mes retours d’expériences. J’ai également pris le soin d’expliquer les termes techniques dans des lexiques en fin de chapitre.
Bonne lecture à tous.
Les différents types de coûts
La gestion des coûts est un élément clé dans la génération de valeur de votre projet décisionnel.
En data et BI, comme dans tout projet informatique, on retrouve des coûts de trois natures différentes, qu’ils soient dans le cadre d’un projet full cloud, full on-premise, ou hybride :
CapEx (investissements initiaux)
- (Cloud) Paramétrage initial, migration des données, configuration des environnements, formation de démarrage.
- (On-premise) Acquisition de serveurs, baies de stockage, réseau, sécurité physique.
- (On-premise) Licences logicielles perpétuelles (bases de données, ETL* on-prem).
- (On-premise) Mise en place datacenter, PRA/PCA*.
OpEx (coûts récurrents)
- (Cloud) Capacités et compute (abonnements Fabric, Snowflake crédits, Databricks DBU, BigQuery, etc.).
- (Cloud) Licences utilisateurs pour outils de reporting (Power BI Pro, Tableau Creator, Qlik Analyzer).
- (Cloud) Exécution des pipelines (ADF, Dataflows, Fivetran, Talend Cloud) → facturation à l’usage.
- (On-premise) Maintenance matérielle (pièces, extensions).
- (On-premise) Contrats de support éditeurs (15–25 % du prix des licences/an).
- (On-premise) Coût énergétique et hébergement (électricité, climatisation, locaux).
- (Les deux) Développement et administration data : création/maintenance pipelines, datasets, monitoring, optimisation.
- (Les deux) Équipe IT interne ou prestataires pour assurer le run.
Coûts indirects
- (Les deux) Mobilisation des métiers (ateliers de cadrage, validation des KPI, tests, retours utilisateurs).
- (Les deux) Conduite du changement (formation continue, documentation, support utilisateurs).
- (Les deux) Obsolescence des compétences et veille technologique : besoin de formation régulière (Fabric, Databricks, Snowflake, etc.)
On a l’habitude de distinguer les dépenses d’investissement des coûts d’exploitation et de run.
Les éléments de la liste définie précédemment peuvent bien entendu varier en fonction des besoins, de vos effectifs, et de votre organisation actuelle :
- CapEx :
- Si vous avez déjà des serveurs existants et que vous partez sur une architecture complètement on-premise, vous aurez d’ores et déjà une base organisationnelle et matérielle pour implémenter votre plateforme, des économies sont donc possibles si vous avez par exemple la possibilité d’exploiter un serveur en sous régime en y installant une ou plusieurs machines virtuelles dédiées ; en y ajoutant si nécessaire de la mémoire physique / du stockage et en réallouant vos ressources CPU.
- OpEx :
- En cas de service cloud déjà existant chez vous, vous aurez besoin de moins de coûts de formation pour vos ressources IT, et vous pourrez éventuellement bénéficier d’un arrangement commercial et bénéficierez d’une gestion centralisée de votre facturation.
Une fois l’investissement initial amorti, en règle générale, les coûts humains (développement et maintenance) restent prédominants, bien souvent partagés entre support interne et expertise externe. Ils nécessitent des compétences souvent pointues, croissantes en fonction de la taille et la complexité de la plateforme (nous reviendrons dans un prochain épisode sur l’aspect ressources humaines et formation).
Vient ensuite le coût des licences et abonnements, fortement dépendant des outils retenus et du modèle tarifaire choisi.
Le troisième poste correspond aux ressources de calcul, facturées selon l’usage cloud ou via la consommation énergétique des serveurs on-premise.
La maintenance, elle, varie en fonction du type d’infrastructure (on-premise, SaaS*, PaaS*, IaaS*, etc.).
Enfin, la formation et la veille technologique sont des aspects à ne pas négliger car le monde de la data évolue très vite d’un point de vue technologique (On peut notamment penser à l’IA, en plein essor commercial).
A titre d’exemple, voici deux situations bien différenciées rencontrées chez des clients illustrant les différents niveaux de complexité du chiffrage :
- Besoins simples de reporting en remplacement d’Excel, utilisation de Power Bi et utilisation ad-hoc de fichiers prétraités.
- Nul besoin d’investir dans des serveurs ou dans une plateforme cloud à ce stade. Les coûts sont essentiellement dirigés vers les quelques licences Pro Power BI, et la formation initiale sur l’outil. Les data analyst peuvent ainsi continuer et partager leur Reporting en bénéficiant d’un nouvel outil plus adapté ; l’industrialisation de la plateforme se fera en fonction de l’évolution de l’activité / des besoins en BI.
En résumé :- Quelques licences Power BI Pro pour une faible redevance annuelle
- Coût variable mais moindre de la formation des utilisateurs (plateformes en ligne, Microsoft Learn (gratuit) ou formation payante de groupe)
- Nul besoin d’investir dans des serveurs ou dans une plateforme cloud à ce stade. Les coûts sont essentiellement dirigés vers les quelques licences Pro Power BI, et la formation initiale sur l’outil. Les data analyst peuvent ainsi continuer et partager leur Reporting en bénéficiant d’un nouvel outil plus adapté ; l’industrialisation de la plateforme se fera en fonction de l’évolution de l’activité / des besoins en BI.
En revanche, j’ai eu l’occasion de travailler pour un grand compte, traitant une forte volumétrie de données très hétérogènes, et à haute fréquence. Base Oracle déjà en place, arrivant à ses limites et nécessitant une administration complexe, flux d’intégration développés sous Informatica, hébergés dans un serveur on-premise, avec des batches quotidiens longs. Dans ce cas, le chiffrage était rendu complexe par les éléments suivants :
- Ici le coût de la migration oracle pèse lourd sur la balance. Mobilisation de 4 administrateurs de base de données, et d’un consultant Oracle externe.
- Passage à des flux Spark avec stockage Hadoop, besoin de recruter des développeurs spécialisés et architectes pour la mise en place.
- Montage d’un cloud privé, scalable mais nécessitant un CaPex important au début (achat de nouveaux serveurs, travaux d’infrastructure, implication des équipes réseaux et sécurité).
Points d’attention : Il est préférable de privilégier le fait de commencer petit, plutôt que de voir trop grand dès le début. J’ai vu nombre de projets ne pas respecter les spécifications initiales, qui pourtant étaient calibrées pour tenir le budget, le temps et les ressources disponibles.
En BI, il est tentant quand on monte un projet de zéro, d’ajouter petit à petit d’autres besoins non initiaux.
Si le scope initial vise le reporting sur le domaine finance, et que d’autres acteurs de la supply chain, du marketing et des ressources humaines souhaitent après coup eux-aussi avoir leurs beaux dashboards (et ils ont raison !), vous risquerez de vous retrouver avec :
- Un volume de données trop important pour le calibre de la plateforme.
- Un besoin de plus de puissance de calcul pour le traitement
- Un coût de développement plus important et des délais allongés (d’autant plus qu’il faudra plus de ressources pour les autres domaines, à la fois développeurs et métiers)
P.S : Le risque avec les solutions cloud, n’est pas le stockage en lui-même : vous pourrez toujours l’augmenter de façon simple et rapide, mais cet espace supplémentaire a un coût certain.
Il n’est pas grave d’omettre certains éléments au départ, mais la grande majorité des besoins doit être identifiée, et donc prévue en matière de coûts.
Dans le cas d’une migration / refonte, il est préférable d’opter pour un double-run pour ne pas créer de rupture de service.
Cela a bien entendu un surcoût ; pour reprendre le dernier exemple, la maintenance de l’ancien système devait persister, le développement de nouveaux projets sur ce dernier était ralenti voire stoppée, et les anciens développeurs Informatica devaient eux aussi « migrer » dans Spark, autrement dit se former !
Lexique intermédiaire :
*ETL (Extract – Transform – Load) / ELT (Extract – Load – Transform) : Outils d’intégration de données.
La différence entre les deux réside dans l’ordre des traitements :
- ETL = les données sont extraites, transformées dans le moteur avant chargement dans la base. Transformations faites sur un serveur intermédiaire.
- ELT = les données sont extraites, chargées brutes, puis transformées dans la base cible via le moteur.
*PRA : Plan de Reprise d’Activité – Instructions organisant le rétablissement total du service après incident.
*PCA : Plan de Continuité d’Activité – Instructions permettant d’assurer une continuité minimale du service pendant un incident.
* SaaS: Infrastructure as a Service – Serveurs, stockage, réseau loués à la demande.
* PaaS: Platform as a Service – Environnement prêt pour développer et déployer sans gérer l’infra.
* IaaS: Infrastructure as a Service – serveurs, stockage, réseau loués à la demande.
Le budget
Le temps où les logiciels de reporting, ETL ou datawarehouse impliquaient souvent un coût très important de mise en place ou de maintenance a laissé place à l’époque des modèles plus légers, self-service, adaptés aux petites et moyennes entreprises.
L’offre cloud s’est fortement diversifiée, rendant la BI beaucoup plus accessible (sans les contraintes financières et opérationnelles de stockage et de maintenance).
Grâce à ces offres, on peut retrancher notamment les coûts d’infrastructure physique indispensable au déploiement d’ETL, base de données, Dataviz et services divers (Middleware*, ordonnancement…).
Ce qui ne signifie pas qu’une plateforme cloud est systématiquement la seule (et meilleure) solution, mais cela permet notamment de se lancer pour les budgets les plus contraints, et également de répartir ses coûts en fonction de la proportion des outils dans son système.
A titre d’illustrations, nous allons voir différents scenarios de coûts estimés en fonction de la taille d’entreprise et des besoins.
Bien entendu, il s’agit d’estimations pour donner un ordre de grandeur : pour disposer d’une estimation complètement fiable, il est nécessaire de réaliser un audit personnalisé et complets, à tous les niveaux.
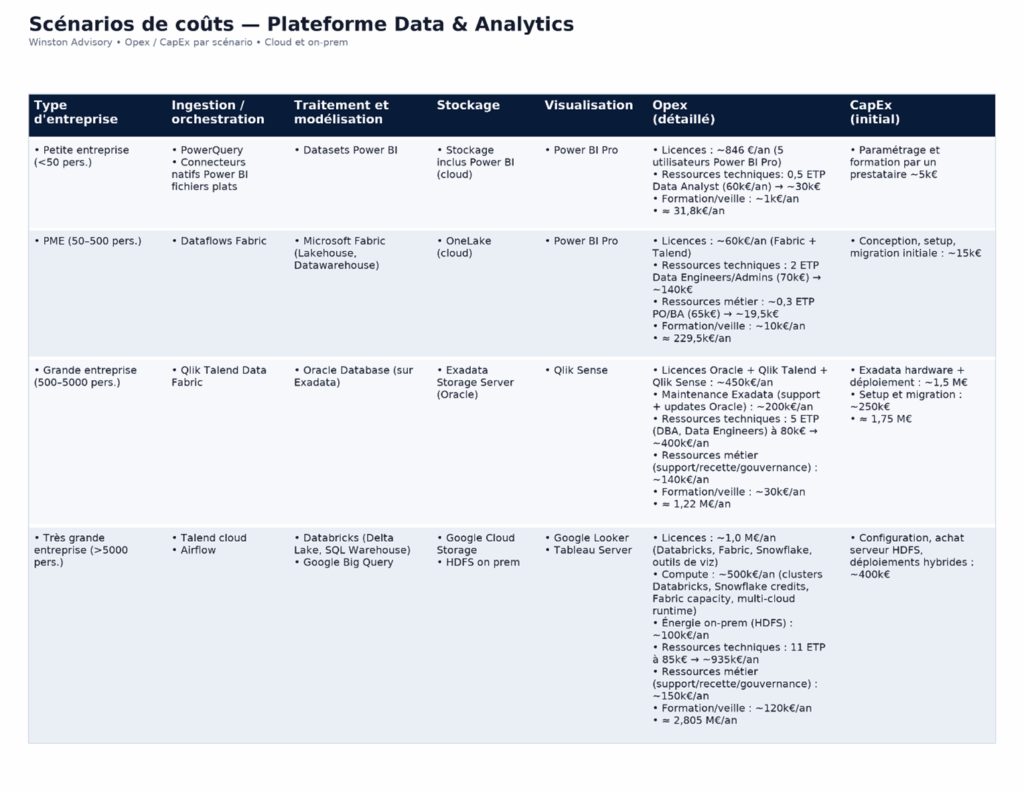
Quelques points à retenir :
Bien comprendre le modèle de prix
Les méthodes de facturation diffèrent en fonction de l’outil et il est nécessaire de bien les comprendre avant de se lancer :
- Par user : prix fixe par utilisateur (ex. Power BI Pro).
- Par capacité : forfait selon la puissance de calcul réservée (ex. Fabric F-SKU, Power BI Premium)
- À l’usage : facturation selon la consommation réelle (ex. Snowflake, BigQuery, Databricks)
La terminologie marketing est parfois difficile à appréhender, il est préférable de se renseigner auprès d’acteurs qui ont testé le modèle de facturation. Votre conseil ou intégrateur peut être de bon conseil à ce sujet.
Par exemple :
Séduite par la promesse marketing d’une facturation “à la seconde”, une entreprise a cru que les coûts Snowflake dépendraient uniquement du volume de requêtes exécutées. En réalité, la facturation repose sur le temps d’activité des entrepôts virtuels : tant qu’un entrepôt reste allumé, il consomme des crédits, même sans requête en cours. Faute d’avoir configuré l’arrêt automatique, les coûts mensuels ont rapidement dépassé les estimations initiales.
Également, bien vérifier si des abonnements supplémentaires à des « supports premiums » ou assimilés ne sont pas parfois compris sans que cela soit très explicite (les packages et abonnements peuvent rapidement devenir des boites noires).
Gérer les pics d’activité
Attention au « burst pricing » : quand on décide de consommer purement à l’usage, et sans réserver de la capacité de calcul bien calibrée, on pense que c’est pratique car scalable à souhait.
Mais les pics d’activité peuvent vite vous faire oublier l’avantage de la souplesse, en faisant monter d’un coup la facture.
Exemple : Fivetran en mode monthly active rows* : un pic d’activité en fin de mois peut se traduire par un doublement de la facture !
Dans ce cas-là, il est préférable de s’engager sur un volume et de gérer le pic avec du dépassement.
Ventiler les coûts
Fixer un budget par produit/équipe et piloter via un contrôle des coûts.
Les grandes plateformes fournissent des outils intégrés : Export Cost Azure, Billing Export GCP, vues COST Snowflake, usage facturable Databricks.
Ces outils permettent de s’assurer que les OpEx soient bien alignés sur les enveloppes budgétaires de chaque service.
Réaliser des POC chiffrés avant de se lancer
Pour éviter les mauvaises surprises, la bonne pratique est d’utiliser un jeu de données de démonstration pour appréhender l’outil et comprendre sa tarification, plutôt que de découvrir le coût total du run après la mise en production. Nous réalisons systématiquement un POC pour nos clients, sur un volume de données cohérent. Et cela sur plusieurs solutions s’il le faut.
Il n’est pas forcément nécessaire de prendre tous les traitements et scope de données : On peut déduire le coût du compute / stockage à partir du jeu de démonstration. J’ai récemment réalisé un POC sur Databricks où la volumétrie avait été sous-estimée d’environ 25 %, et où quelques traitements coûteux avaient été oubliés initialement : la facture a doublé par rapport à l’attendu.
Gérer intelligemment le “on/off” des environnements
Des solutions existent aujourd’hui pour automatiser la mise en veille et le redémarrage des environnements, selon leur niveau d’activité. Databricks propose un auto-suspend* après inactivité, Snowflake gère l’auto-suspend / auto-resume*, et Fabric permet de mettre en pause les capacités hors heures ouvrées.
De mon point de vue, il est pertinent d’exploiter ces mécanismes, surtout sur les environnements de développement et de test, souvent laissés allumés sans raison.
Je conseille également d’étudier la possibilité de les étendre à certaines zones de production non critiques, à condition de bien mesurer les impacts sur les flux et les utilisateurs.
Enfin, je recommande de s’appuyer sur les logs d’usage et de compute pour identifier les créneaux réellement inactifs et affiner les automatisations. C’est, selon moi, une bonne pratique pour réduire les coûts sans rogner sur la qualité de service.
Calibrer la fréquence d’actualisation des données
Si l’on souhaite du temps réel sur certains tableaux de bord, il faut d’abord vérifier que le retour sur investissement est justifié. Le temps réel implique un coût technique élevé : ressources, complexité d’architecture, surveillance et maintenance continue.
Je recommande de bien distinguer les différents niveaux de fraîcheur des données :
- Temps réel : indispensable uniquement pour le suivi instantané d’activités critiques (ex. supervision d’incidents, transactions financières).
- Quasi-temps réel : quelques minutes de décalage, souvent suffisant pour le pilotage opérationnel (ex : suivi en clôture financière)
- Intra-journée ou quotidienne : adapté à la majorité des usages décisionnels « traditionnels »
Dans tous les cas, c’est le besoin fonctionnel qui doit dicter la latence acceptable, pas l’inverse. Dans de nombreux cas, un mode semi-temps réel ou un rafraîchissement à la demande couvre largement les attentes tout en maîtrisant les coûts.
Éviter les coûts cachés
Les flux sortants de données (terme technique = Egress*) peuvent se révéler coûteux quand on sort de sa zone d’hébergement (dans une même région ou infrastructure, le coût est moindre). Attention également aux multiples fichiers de logs et à la rétention de fichiers archivés, qui peuvent vite peser lourd sans une gestion efficace.
L’importance de la négociation
Dans le cadre d’un engagement de plusieurs années, il est attendu de demander des remises par palier ainsi qu’un tarif protégé sur la durée.
Idée : passer du modèle on-demand* de Snowflake (prix catalogue par crédit) à un engagement RI* + paliers de volume.
Effet : remise via l’engagement et remise due au volume ⇒ ~−20 à 30% de réduction potentielle vs on-demand.
C’est un investissement pouvant être important mais qui peut s’amortir en quelques années et diminuer vos running costs.
Anticiper les impacts et assurer la veille technologique
Des évolutions technologiques ou de positionnement produit peuvent changer la donne sur votre architecture et mettre quelques grains de sable dans les rouages.
Essayez de consacrer du temps pour assurer une veille technologique continue : En ce qui concerne les outils que vous utilisez, mais pas seulement.
Abonnez-vous à des newsletters ou alertes, soyez au fait des dernières informations et roadmaps des éditeurs du marché.
Cela vous permettra d’anticiper les impacts parfois compliqués à gérer quand le délai disponible est court, comme une migration forcée à cause d’une montée de version, d’une dépréciation, ou d’un arrêt du support…
Faites donc en sorte de prévoir une marge pour absorber ces évolutions non anticipées.
Un exemple récent :
La fin de vie annoncée du mode Standard de Databricks : tous les workspaces Standard seront migrés automatiquement vers le niveau Premium à partir du 1ᵉʳ octobre 2026.
Impacts directs sur la facturation (20 à 25% en + pour le même usage), et sur les coûts d’administration des nouvelles fonctionnalités.
Pour bien gérer le budget de votre projet, il est crucial de bien définir en amont (comme tout autre investissement), votre enveloppe, initiale et sur la durée (CapEx et OpEx cités précédemment). Il est prudent de prévoir légèrement plus notamment sur les abonnements cloud pour lesquels les estimations de consommation théorique vs réelle sont difficiles.
Les perspectives de croissance de l’activité et d’exposition de nouveaux domaines de votre univers data, doivent être anticipées, au risque de bloquer les nouveaux projets et d’avoir besoin de se lancer dans un chantier de refonte complet ultérieurement.
Il existe toujours une solution qui saura rentrer dans votre budget pour bénéficier une BI opérationnelle. Simplement, l’investissement initial déterminera la robustesse de votre data platform et l’ampleur de vos running costs futurs, mais il n’est pas rare et souvent préférable d’avancer par étapes et de découper la construction de la data plaform en sous-projets.
Lexique intermédiaire :
* Middleware – Couche logicielle intermédiaire entre les applications qui sert à les faire dialoguer directement (ex. API Gateway, Enterprise Service Bus).
* Monthly active rows – Compteur utilisé par certains outils (comme Fivetran ou Fabric Data Activator) qui permet de mesurer la facturation selon le nombre de lignes de données modifiées ou chargées chaque mois.
* Auto-suspend – Fonction de mise en pause automatique d’un service ou un entrepôt (ex. Snowflake, Databricks) après un certain temps d’inactivité.
* Auto-resume – Fonction complémentaire qui permet de relancer automatiquement le service dès qu’une requête ou un job arrive.
* On-demand – Mode de facturation au tarif catalogue, qui se base sur la consommation réelle.
* RI : Reserved Instance – Modèle d’engagement où une capacité est réservée à l’avance et pour une durée déterminée, contre potzntielle remise par rapport à du on-demand.
Les bénéfices
Après ce tour d’horizon des coûts d’un projet décisionnel vient la dernière partie où nous allons aborder les bénéfices attendus de la plateforme.
Bien entendu, cela dépendra de la nature de l’activité, de l’investissement initial, de l’organisation et de l’utilisation qui sera faite de la plateforme
Nous vous présentons ici quelques-unes des fonctionnalités que nous avons mis en place chez nos clients, orientées principalement finance & performance, et qui illustrent certains des nombreux avantages que peut apporter une plateforme solide de Data Analytics.
Réduction des coûts opérationnels
- Automatisation des reportings = moins de temps passé par les équipes à consolider Excel.
- Monitoring des flux (supply chain, production) en temps réel
Amélioration de la performance financière
- Capacité à analyser les écarts entre prévisionnel et réalisé, avec un drill-down jusqu’au centre de coût
- Meilleure visibilité sur la trésorerie, le cash-flow, les marges.
- Détection précoce d’anomalies, monitoring de la qualité des données.
Optimisation des investissements
- Centralisation des données => pilotage plus fin des projets d’investissement (CapEx/OpEx).
- Scénarios de simulation (prévisions, what-if analysis*)
Maximisation des revenus
- Ciblage commercial et marketing plus précis (meilleur ROI campagnes).
- Suivi en temps réel des ventes et des marges.
- Mise en place de KPIs détaillés de marge par produit, par segment de clients, par magasin.
Meilleure gouvernance et maîtrise des coûts cachés
- Gouvernance centralisée = moins d’erreurs humaines, moins de shadow IT.
- Conformité réglementaire (RGPD*, ESG*, SOX*)
- Standardisation = moins de dépendance à des outils isolés ou à des fichiers Excel non sécurisés.
En tant que Data Architect chez Winston Advisory, je suis souvent amené à intervenir auprès d’une population finance / controlling / comptabilité chez qui nous avons automatisé des process lourds en temps de travail, et générateur d’erreurs humaines.
- Plusieurs jours de libérés par mois pour la communication des reporting financiers
- Des données de P&L mises à jour plusieurs fois par jour, nécessitant auparavant des extracts / loads constants
- Des données croisées entre ERP, consolidation et prévisions budgétaires : trois systèmes, une seule vision, sans jongler entre trois fenêtres ni recopier dans Excel.
La BI finance, en faisant gagner du temps de travail sur le traitement de l’information, permet de repositionner les équipes sur des activités porteuses de sens (analyses critiques, bridges, participation à la prise de décision).
En dehors de l’univers finance, j’ai personnellement mené d’autres projets dans des secteurs variés, où le développement de projets BI s’est révélé générateur de valeur bien au-delà de l’investissement initial, aussi important qu’il fût.
Illustration
Par exemple, dans un groupe industriel disposant d’une logistique à grande échelle et des stocks de matériel qui se chiffrent en centaines de millions d’euros, qui faisait face à des problèmes récurrents : matériels égarés, pièces défectueuses non tracées, délais fournisseurs mal suivis.
Solution : la mise en place d’un datamart logistique sur une plateforme existante alimenté par :
· Des données SAP logistiques (stocks, commandes, livraisons),
· D’autres systèmes internes (gestion du matériel, IoT terrain, maintenance).
L’objectif était d’assurer une traçabilité complète des matériels, de la production jusqu’au terrain.
Résultats concrets après 2 ans de projet :
· Forte réduction des pertes de matériel, plusieurs centaines d’articles retrouvés et réintégrés dans la chaîne (dues notamment à des problèmes de scan initiaux)
· 15 à 20 % de baisse des délais de livraison fournisseurs grâce à un meilleur suivi des commandes
· Amélioration du process de scan des techniciens et de l’inventaire dans les entrepôts
Un projet long de deux ans qui justifie largement l’investissement initial avec des retombées durables et mesurables.
Lexique intermédiaire
* What-if analysis – Simulation de scenario pour mesurer l’impact de certaines variables sur un modèle.
Ex : En finance, tester l’effet d’une hausse de 10 % des ventes sur les bénéfices
* RGPD : Règlement Général sur la Protection des Données : législation de l’UE sur la collecte, le traitement et la conservation des données personnelles.
* ESG : Environmental, Social, Governance) – Score d’évaluation extra-financiers d’une entreprise basée sur des critères environnementaux et sociaux.
* SOX : Sarbanes–Oxley Act – Loi américaine imposant des contrôles internes sur la production de données financières des entreprises cotées.
Conclusion
En synthèse, le véritable enjeu d’une plateforme data et analytics n’est pas seulement de savoir combien elle coûte, mais surtout de mesurer ce qu’elle rapporte. Trouver le bon équilibre entre investissements, usages et adoption est indispensable pour la viabilité de votre projet.
Je vous partage ci-après ma liste de points clés pour réussir votre projet de data platform décisionnelle :
- Cadrage : définir précisément avant toute chose besoins et périmètres pour éviter les dérives
- Optimisation : Monitorer et ajuster les ressources et licences selon le besoin
- Utilité : Concentrer les investissements sur les outils générateurs de valeur
- Transformation : assurer une veille continue pour anticiper évolutions, formations et opportunités tarifaires
- Suivi : mesurer dans le temps l’efficacité et le retour sur investissement